软件工程师使用ChatGPT日常——高效理解技术细节
问题
最近在整理一些关于Helm在大型企业中实践的内容,突然想到一个关于Helm的最佳实践:
Chart names must be lower case letters and numbers. Words may be separated with dashes(-)
在各种软件产品中,我不止一次看到对于大小写,破折号/下划线的要求。这次看到Helm的最佳实践,我依然很疑惑——为什么不使用大写字符和破折号会成为一个最佳实践?如果说为了命名风格一致,但为什么甚至会在某些软件中被直接禁止?比如Helm在install时如果存在大写或者下划线会直接报错。
关于这个问题我尝试使用传统的搜索引擎,但并不能很好的找到答案: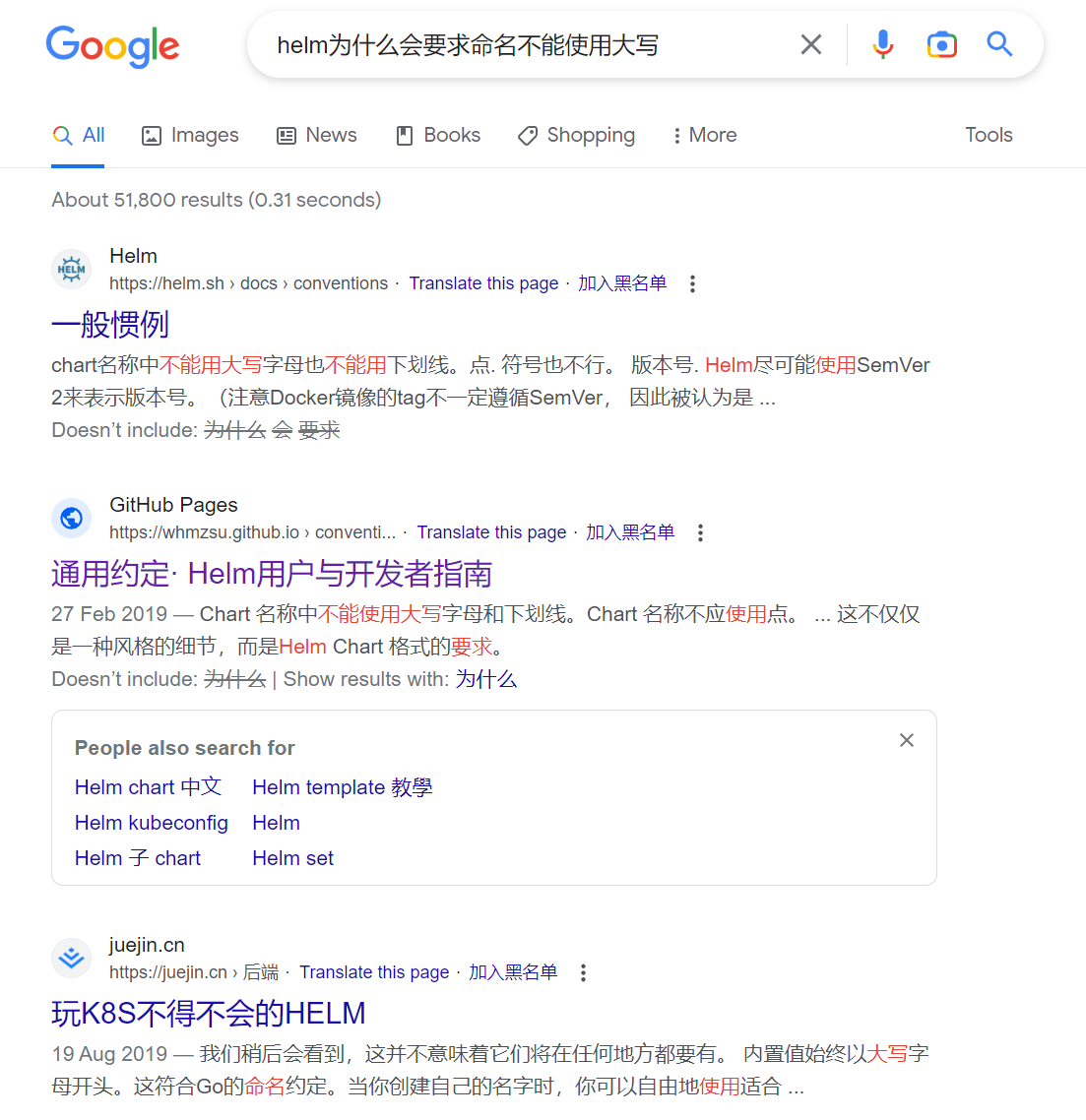
通过ChatGPT来搜索答案
从上图可以看到,搜出来的结果基本都是重复官方要求的不能使用下划线和大写字母。如果利用ChatGPT来找答案,是否能得到一个更好的答案呢?
以下是我的对话记录:
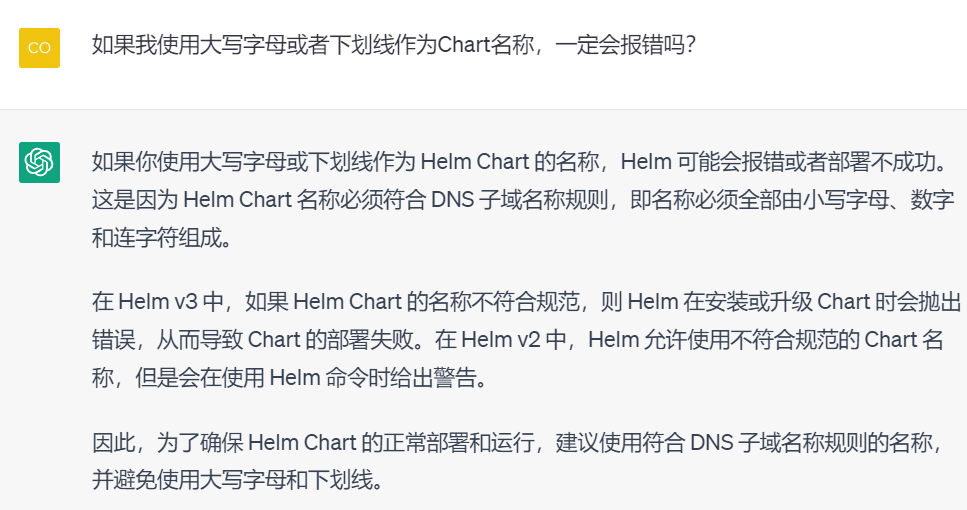
从回答中可以看出是因为Kubernetes的命名规范限制了作为工具的Helm的命名,这很好理解。但是Kubernetes为什么会要求命名不能使用大写呢?继续追问:
经过两轮对话,ChatGPT已经给出了关键原因:为了避免操作系统中对于大小写不一致的处理方式可能会导致无法正确识别和处理对象。当然这也不够直接,继续问一个更具体的案例:
到这里,答案基本就明了:在Linux中能够创建myFile.txt和MyFile.txt的两个文件,但是如果同样的创建方式在Windows中执行一遍,就会出错。因此就有了通过规定只允许小写字母来避免这样的问题发声。
总结
整个过程,只用了大概2分钟,如果使用传统的搜索引擎,我并没有办法很快找到答案。ChatGPT在解决这个问题上有很大优势。 但ChatGPT在处理这样的日常任务时就完全没有缺点吗?当然不是。有以下这几个问题:
提问(Prompt)的方式决定回答的质量
相比于传统的搜索引擎靠关键字的方式,ChatGPT的问题方式事实上变得复杂了很多,同时也变得尤为关键。你描述的详细程度,描述的方式发生变化,得到的答案也不一样。同一个问题,我换一种问法,如下图所示:

回答的准确性
有时候ChatGPT的答案并不准确,相比之下,有一个靠谱的网站背书+一定数量的评论,这样的答案可信度更高。而ChatGPT的回答,比如:
准确的回答就一定好?
我并不觉得准确的回答就一定好。很多时候我们使用搜索引擎去尝试解决一个问题,不只是为了解决问题本身,也希望能够从解决问题的过程中学到一些相关的知识,但是直接了当的回答,是否会一定程度的限制我们想象力的衍生呢?
当然总的来说,将ChatGPT当作一个高级的搜索引擎来解决一些具体问题,的确是能够提高效率的,可以一试。